
新趨勢SEO文章9步驟,學正確寫作結構幫你快速在google首頁排名
SEO文章是依照搜尋意圖撰寫、且結構符合...
Read more
Stable Diffusion是一種基於AI的圖像生成技術,在快速發展的AI時代,圖像生成技術已成為各行各業趨勢之一。究竟如何在眾多的AI圖像生成平台中,找到一個既簡單易用又具備高品質輸出的工具呢?本文將帶您深入了解Stable Diffusion,一個專為您量身打造的創意圖像生成平台。從登入過程到圖像生成及調整,我們將為您提供詳盡的操作指南,讓您一探究竟,輕鬆掌握這項強大的技術。
這篇文章還會介紹4種安裝方式與從基礎到進階的使用方式:
推薦使用Google Colab安裝Stable Diffusion的原因除了簡單、好用以外,最重要的是客製化程度非常高,學會正確關鍵字,你可以做出非常多符合期望的圖片。

看完本篇可以學到:
Stable Diffusion是一種基於AI的圖像生成技術,它通過將圖像逐步從高度隨機的噪聲狀態進行重建,最終生成一個清晰的圖像。這種技術可以用於生成各種風格和主題的圖像,如風景、人物、建築等,並能夠根據特定的指令生成具有特定特徵和風格的圖像,甚至催生了新職業ai詠唱師。Stable Diffusion在AI圖像生成領域具有很高的潛力,並且因為其免費和易用的特點,受到許多創作者和設計師的青睞。
關於Ai詠唱師可參考 認識Ai詠唱師:21世Ai電繪新職業。培養3種賺錢技能

下載Stable Diffusion懶人包。懶人包包含兩個部分:SD-WebUI啟動器和數據整合包。
解壓縮SD-WebUI啟動器:下載完成後,將SD-WebUI啟動器解壓縮並放入數據整合包中。
安裝相關檔案:在安裝Stable Diffusion之前,可能需要安裝一些相關的檔案。請確保您已經安裝了Python和Anaconda。
環境配置:在安裝過程中,需要進行一些環境配置。在Windows 11環境下進行安裝,使用CPU內顯。記憶體需要2條16GB 3200 MHz,硬碟建議預留30GB以上的空間。
啟動Stable Diffusion:將SD-WebUI啟動器放入數據整合包中後,運行SD-WebUI啟動器以啟動Stable Diffusion。這樣可以讓您無需手動啟動各個腳本,即開即用。該網站還包括軟件更新、中文化、管理模型和疑難掃描等功能。
需要時間: 12 分鐘
4步驟部屬Stable Diffusion到Google Colab
在 Github 會有很多已經寫好檔案可以直接一鍵使用,camenduru製作的stable-diffusion-webui-colab是目前最多模型可供選擇的地方:
訓練好的Stable Diffusion模型ChilloutMix是目前亞洲最多人使用的,作出來的圖片成效非常逼近真人,也因為裡面都是用韓星進行訓練好的模型,偏向亞洲人的喜好;可在Github頁面直接搜尋ChilloutMix。
這邊是一些我用Chillout做出來的圖片
另一個推薦的是Perfect World,做出來的效果也很棒
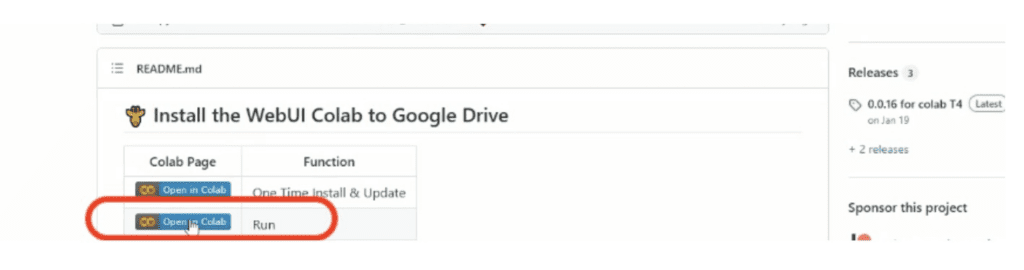
找到『chillout_mix_webui_colab 』,點中間那個寫stable的小圖示後會自動跳轉到Google Colab 頁面,不止Stable Diffusion直接可以一鍵部屬,連進階plugin ControlNet都安裝到位。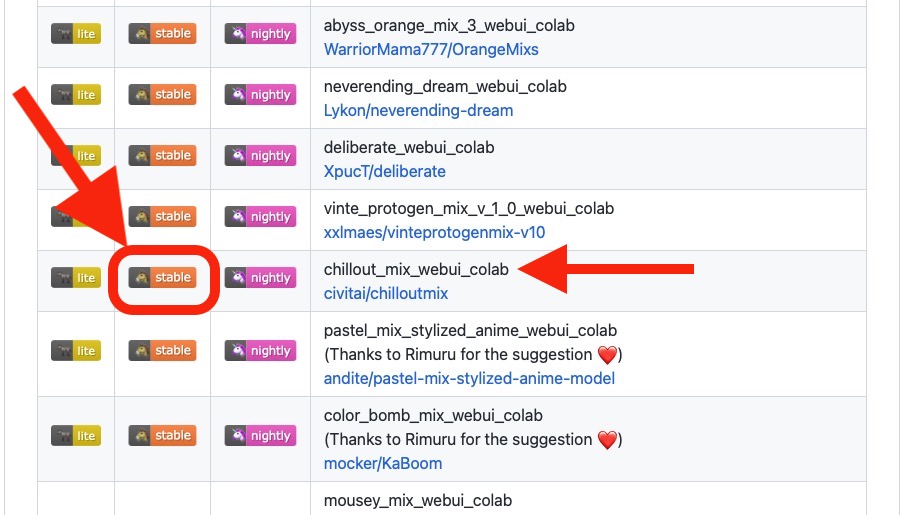
到Google Colab頁面,點選畫面左上方的執行按鈕
點下開始運行後會需要確認執行,確認後Stable Diffusion就開始在 Google Colab部屬囉,大約7分鐘以內就可以完成。
判斷完成的方式很簡單,看到頁面下方出現兩行網址就是安裝完成囉!兩個網址都能點擊,都會一樣到運行於Google Colab的Stable Diffusion網頁版頁面(WebUI)。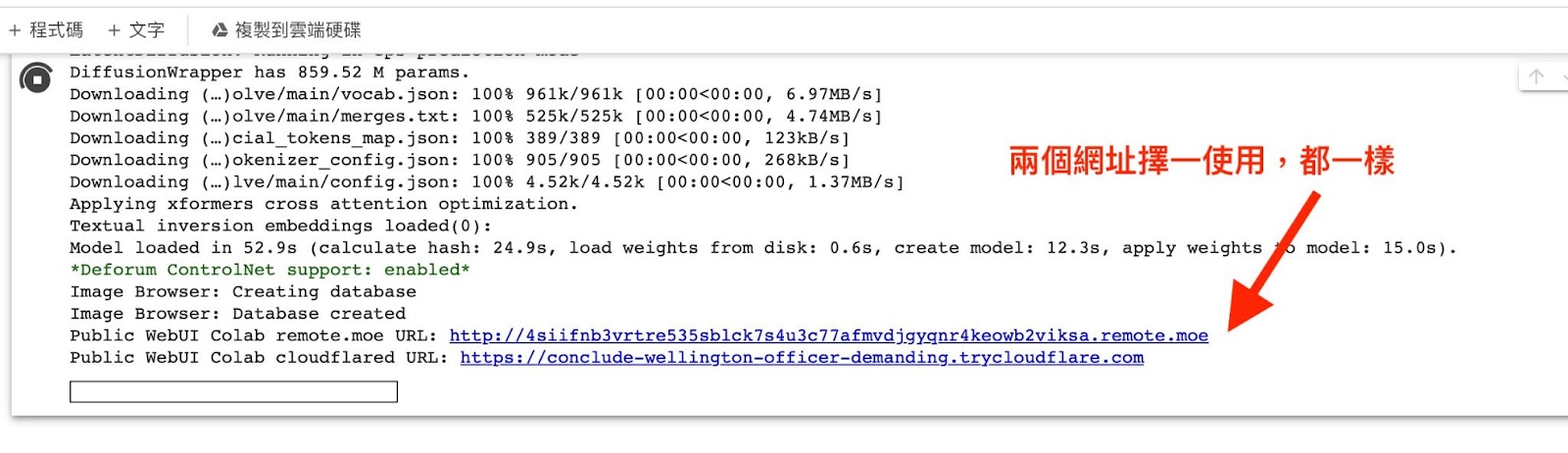
*注意,每個Google帳號每天有做圖運算額度限制,超過使用量可以換另一個帳號馬上繼續用,或是維持原帳號等24小時後再用。
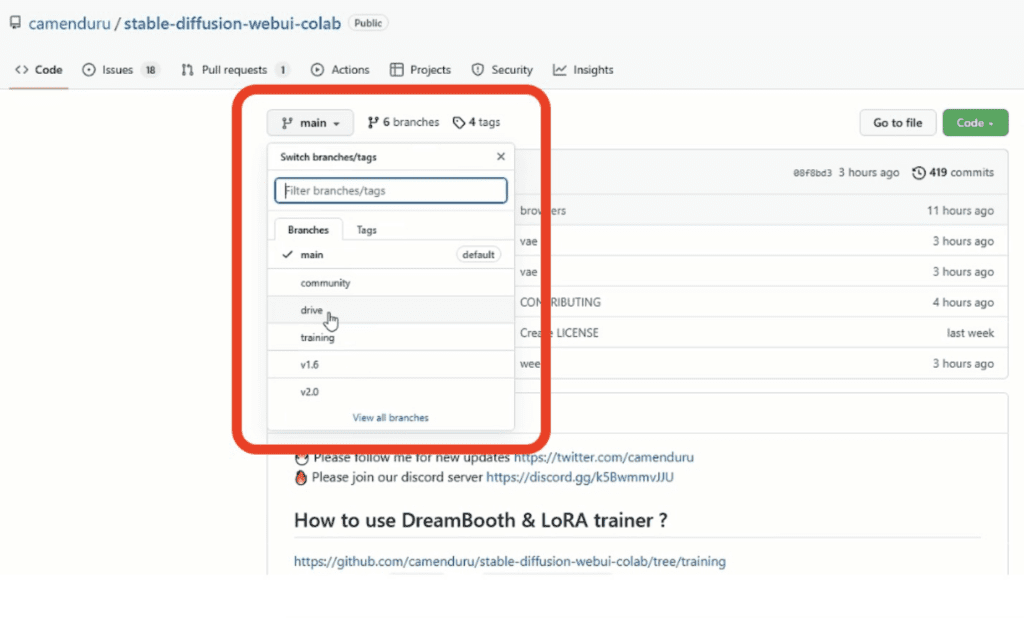
先打開camenduru製作的stable-diffusion-webui-colab筆記本,從下拉選單找到Drive,按著ctrl點擊按鈕用新頁面開啟,接著複製到自己的Google Drive雲端硬碟上。
P.S. 以下是簡易說明,詳細手把手安裝方式可以參考 Stable Diffusion安裝Google Drive運作colab
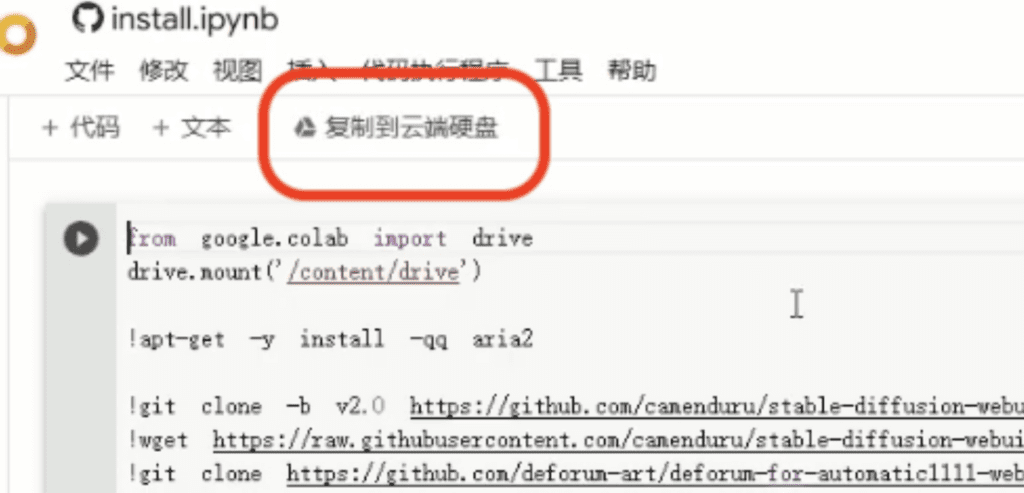
執行複製到Google Drive上的安裝檔副本,安裝後如法炮製也把執行檔(第二個檔案)複製到Google Drive並執行
接著就能正常使用Stable Diffusion WebUI囉!打開Stable Diffusion WebUI,這是在你的Google Drive上執行,用法跟本機安裝或直接Colab執行的Stable Diffusion一樣,也都能裝擴充功能。
把Stable Diffusion安裝在Google Drive的好處是完全走雲端,不用用到電腦資源或高階顯卡,即使Google Colab關閉後會清空資料,但因為是安裝在Google Drive上,所以畫好的圖不用每張都用右鍵儲存,直接在output目錄可以找到。
安裝在Google雲端上並執行Stable Diffusion非常方便,除非作者有更新才要重新安裝,不然只要安裝一次,未來使用只需運行run.ipynb腳本就行了囉。

Stable Diffusion是一個免費的開源軟體,專門用於生成圖像。儘管許多人可能不知道如何安裝和使用這個軟體,但我們可以通過一些現成的服務來使用它。
一種使用Stable Diffusion的方法是訪問官方網站Dream Studio。在這個平台上,用戶可以免費生成大約一百張圖像。
使用Dream Studio步驟
通過以上步驟,您可以輕鬆地使用Stable Diffusion網站,進行圖片生成。
另外一種使用方法Stable Diffusion Demo,進入到「Stable Diffusion Demo」網站即可看見指令輸入欄位,或是網頁下方也有一些案例可以參考。

Dream Studio與Stable Diffusion Demo比較
在兩邊用一樣的指令:A high tech solarpunk utopia in the Amazon rainforest,左圖是Stable Diffusion Demo版本,右圖是Dream Studio版本。


指令比較測試:A pikachu fine dining with a view to the Eiffel Tower



我把用ChatGPT量產高品質文章的方式更新到流量變現的SEO課程囉,實際demo,超過2小時ChatGPT教學,教會你用 ChatGPT 快速產出文章且快速上首頁的方式👉學會6天18篇文章上首頁,幫你帶來更多客戶!
我們會在Stable Diffusion 的 WebUI 介面,輸入關鍵字、咒語與調整調整參數來產圖。以下教學使用Perfect World模型當案例。
當 Stable Diffusion 網頁版介面建立好,首先左上角可以看到現在使用的模型,接著中間是讓我們能夠跟Ai溝通的核心區域:關鍵字咒語輸入區。Stable Diffusion關鍵字,英文是Prompt,又稱為Stable Diffusion咒語。
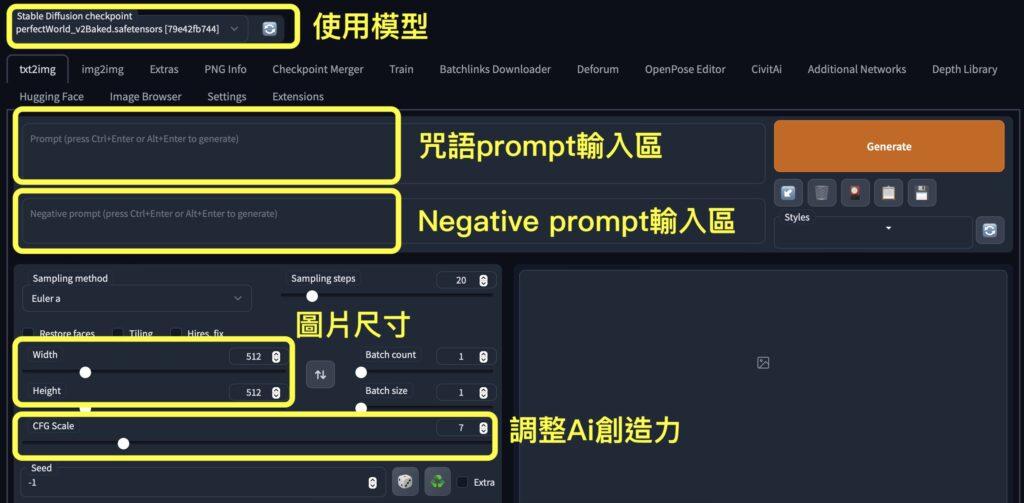
這邊有兩個區塊:
下方的敘述則是圖片寬度、高度、產生幾張圖等設定,如果你算出來的人物壞掉再勾選 Restore Face即可,我通常不用這個功能
CFG Scale則是告訴Ai他繪圖的自由度,數字越小表示越自由創作,越大則表示需要更遵守你的咒語關鍵字,我通常會使用6.5,而當靈感枯竭時會調整到3:建議Stable Diffusion的CFG Scale使用3~7即可。
提供兩個我畫的圖片使用的咒語prompt與Negative Prompt
realistic 8k, picture-perfect face, flawless, clean, masterpiece, professional artwork, famous artwork, cinematic lighting, cinematic bloom, perfect face, beautiful face, beautiful eyes, ((perfect female body, narrow waist)), fantasy, dreamlike, unreal, science fiction,1girl, intricate detail, delicate pattern, sexy, charming, alluring, seductive, erotic, enchanting,
smiling, looking away, pink hair, undercut, apron, amazing body, 1girl, corset, cinematic, (portrait), sideface, foreshortening, breasts, cleavage, full_body, high_heels, long_hair, solo, depth_of_field, outdoors, realistic, photo_\(medium\), photorealistic, (ultra-detailed:1.2), ((high ornamented dress)), detailed light, HDR, Empire_dress, (awaitingtongue:1.2), ((realistic)), photo referenced, highest quality, high quality, (detailed face and eyes:1.1), ((goth)), golden hour, freckles, queen dress, green royalty, green eyes, full body, red dress,((crown)), thin lips, victorian clothes, highly detailed clothes, green engravings on clothes,on the street, (embarrassed laughing:1.2),
emphasizing her curves and sex appeal, The overall tone of the image is dark.
上述prompts可以直接複製使用先熟悉Stable Diffusion運作,要學會精準使用關鍵字,可以參考 Stable Diffusion 咒語關鍵字全解析
當然prompt可以讓ChatGPT幫你寫,請參考 1個就夠!Ai繪圖prompt生成器,你只需要它:ChatGPT
Negative Prompt直接複製貼上即可,說明不要出現一些刺青、品牌、標語、醜臉和6根手指頭等等。
(deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation. tattoo,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, out of focus, censorship, ugly, old, deformed, amateur drawing, odd, bad hands
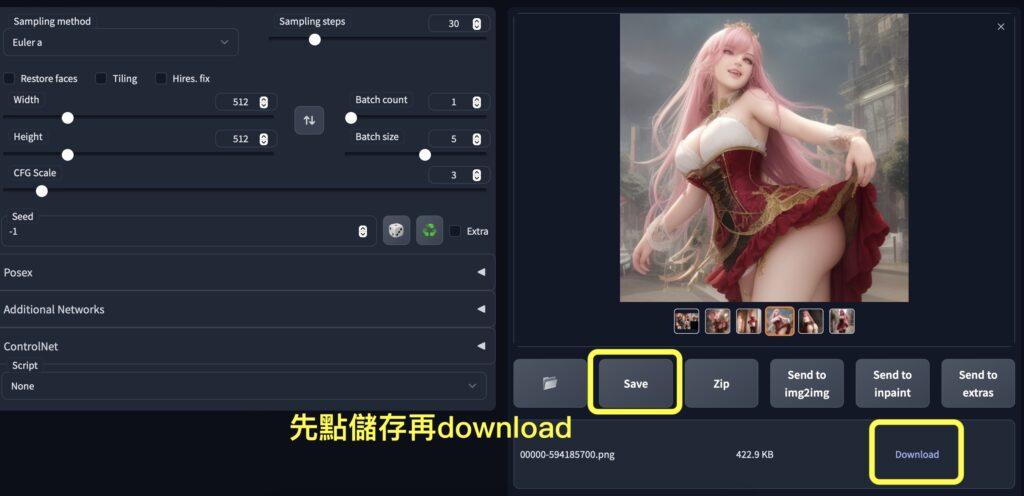
按下執行『Generate』產生圖片:


工作區右下角,點擊任何一張就會顯示大圖,你可以直接右鍵存到電腦裡,也可以透過下方的 Download 按鈕下載,圖片只會保存一小段時間喔。
如果你想看Ai女主角的背面,用跟上面教學一樣的咒語再加上動作提示,例如:back to viewer(背對鏡頭),女主角有一樣風格但畫面呈現結果完全不同。寫prompt跟寫文章一樣重要,而且都是有邏輯性的,可以參考 stable diffusion prompt 教學,解釋prompt使用規則、符號、參數與範例

以髮型、髮色與頭飾為案例,以下是一個表格,用來說明可以將英文中括弧標示的文字進行替換。以髮型為例,您可以將 “undercut” 替換成其他髮型,如 “ponytail”。
hair style[undercut], [red] hiar, [crown],dress style [Goth], [in a classroom],下表列出於括弧內可供替換的關鍵字
| 類別 | 替換選項 |
|---|---|
| 髮型 | undercut, ponytail, bob, pixie, braid, mohawk, dreadlocks, bun, shag, wavy, straight, curly, pompadour, slicked back, side part, quiff, top knot, mullet |
| 髮色 | red, black, brown, blonde, gray, green, blue, purple, pink, orange, balayage, highlights, pastel, burgundy, ombre, ash blonde |
| 頭飾 | crown, hat, headband, beret, baseball cap, beanie, fedora, turban, veil, bonnet, hairpin, headscarf, fascinator, tiara, bow |
| 服裝風格 | Goth, casual, business formal, vintage, athletic, hip hop, rock, mori girl, military, bohemian, country, beachwear, retro, kimono, hanfu, ethnic |
| 地點/背景 | in a classroom, in a studio, at the beach, in a forest, on a mountain, in a city, in a park, in a garden, at a party, in a cafe, in a library, at home |
這邊只展示了一些可以替換的選項,建議可以參考更完整的 Ai繪圖關鍵字查詢和大量實際案例|瘋狂整理持續更新
以上教學模型是Perfect World,比較偏向電腦畫作,而模型到ChilloutMix是真人,如果把一樣Stable Diffusion咒語關鍵字放到ChilloutMix中能得到的結果是?….依照本篇教學自己操作一次就知道了。下方放小圖案例供您參考。P.S.我把髮型從undercut改成綁馬尾ponytail


一樣風格的服裝,在情境設定加上 happy 的效果

用一樣服裝與圖片風格但換轉換場景,加上穿西裝的攝影師,變成cosplay現場
使用Stable Diffusion生成圖像,可以根據指定的條件和約束生成高質量的圖像。它可以用於創建合成圖像、生成特定主題的圖像,例如人臉、風景或動物等,或者生成獨特風格的藝術作品。通過合理調整相關參數,可以生成具有不同細節、顏色和風格的圖像。
以下圖為例,左邊是用prompts生出的原圖,中間與右邊是透過img2img功能,維持同一個主角,針對背景、髮型、服裝進行修改。

Stable Diffusion img2img功能非常適合大量替換圖片背景或人物服裝的場景。通過使用適當的遮罩,用戶可以選擇保留圖像的某些部分,例如人物或物體,同時替換其他部分,如背景或服裝。此外,通過調整相關參數,用戶可以控制生成圖像的細節程度和風格,實現最佳的視覺效果。
img2img使用步驟如下:
這邊有一篇手把手教學的案例,教你從換背景到換服裝,到整個圖片風格換掉,一次學會。完成這過程只要5分鐘 👉 Stable Diffusion img2img 教學,以圖改圖換臉、換服裝、換背景或風格(附大量案例)

原圖,背景在巴黎市區的公寓陽台

背景從巴黎公寓陽台換到紐約高樓

換到室內,並一套衣服
除了以上提到的範例,還有一些其他模型和插件可以在Stable Diffusion WebUI中使用。例如,Canny插件可以用演算法細緻地抓取圖片的邊緣線,作為參考來生成新圖像。另外,有一些模型專門針對特定的主題或風格,如Civitai | Stable Diffusion models,這個網站上提供了不同風格的模型,可供使用者選擇。
Stable Diffusion 的原理涉及深度學習和生成對抗網絡(GAN)技術。生成對抗網絡包含兩個神經網絡,生成器和判別器,它們相互競爭以提高彼此的性能。生成器的目的是創建越來越逼真的圖像,而判別器則要將生成的圖像與真實圖像進行區分。
在 Stable Diffusion 的過程中,生成器通常會接收一個隨機噪聲向量和描述圖像的文字輸入。這些輸入將被轉換成圖像特徵,然後經過多層神經網絡生成逼真的圖像。與此同時,判別器會評估生成的圖像和真實圖像之間的差異,並給出一個概率分數,表示生成的圖像的真實性。生成器和判別器之間的競爭將持續進行,直到生成器創建出高度逼真的圖像。
Stable Diffusion 在這一過程中可能還利用了其他額外的技術,如自注意機制(self-attention)和梯度懲罰(gradient penalty),以提高生成圖像的質量和穩定性。
進行Stable Diffusion訓練的目的是為了讓AI生成模型能夠生成更高品質的自然圖像和藝術作品。在訓練過程中,模型會使用大量真實圖像來學習如何從隨機向量生成高品質圖像。有時候,單靠預設的模型可能無法達到使用者期望的畫風或效果。因此,進行訓練可以改善這些問題,使得生成的圖像更貼近使用者的需求。
訓練Stable Diffusion模型可以擴展其應用範疇,使其能夠支持特定的風格或需求。例如,有些使用者可能希望生成具有特定風格或主題的圖像。通過對模型進行訓練,可以使其能夠生成符合使用者期望的圖像。此外,訓練過程可以涉及不同的技術,如Textual Inversion (Embedding)、HyperNetwork、LoRA等,這些技術可以為生成的圖像提供更多的控制和細節。
為了成功地訓練和生成Stable Diffusion模型,需要一個高性能的計算平台,包括高階GPU、大量記憶體、存儲空間和計算能力。此外,還需要安裝相應的機器學習框架和庫,例如PyTorch、CUDA等,並熟悉這些框架的使用。不過,現在有許多開發者已經創建了各種風格的模型供大家使用,用戶也可以自己訓練出自己喜歡的風格模型。
Stable Diffusion的訓練方法涉及多種技術,包括Textual Inversion(Embedding)、HyperNetwork和LoRA。在訓練過程中,模型使用大量真實圖像來學習如何從隨機向量生成高品質圖像
訓練Lora模型的步驟較為複雜,需要分為四個小步驟
基本步驟:
stable diffusion下載模型的網站 Hugging Face和civitai ,CivitAi能看別任做的圖,能看到prompt細節,還能直接下載別人訓練好的模型。

Stable Diffusion看圖網站 MajinAI ,這邊有很多人分享AI繪圖。
PixAI.Art 可以直接看圖也能線上算圖

Stable Diffusion以其直觀的操作界面、豐富的圖像生成選項和便捷的調整功能,成為了一個值得一試的AI圖像生成平台。無論您是專業的設計師、創意工作者,還是對AI圖像生成感興趣的初學者,Stable Diffusion都能為您提供靈活的創作選擇和極具吸引力的視覺效果。
在這個AI技術不斷創新的時代,Stable Diffusion將持續為您帶來更多令人驚艷的圖像生成體驗,激發您無限的創意潛能,助您在藝術與科技的交匯處,揮灑出獨具匠心的作品。
你可以靠SEO『壟斷』你的領域,搶下大量關鍵字排名,讓人們想到某類型知識、課程、主題就想到你!
不過話說回來,學SEO是達成目標的手段,那你的目標是什麼?打算怎麼把流量變現?
常見方式有銷售線上課程、電商賣產品或聯盟行銷;但電商賣產品要壓庫存風險高、轉單利潤太低、聯盟行銷要長期經營,而我推薦製作線上課程/提供顧問服務,把知識變現:毛利95%以上、0庫存風險、靠自動化系統你自己一人就能搞定,還能用預售方式提早收錢建立健康現金流。
我在這堂課程中把線上課程與SEO結合起來,一次教你:【專注流量變現】製作線上課程+新趨勢Ai SEO技巧當護城河。
你將學會:
還免費提供變現工具:送Tutor LMS Pro、送wordpress模版Astra Pro、送網站加速外掛WP ROCKET。官方售價共美金$617,課程中免費提供。
P.S. 我也能免費幫你把網站做到位。這樣做是因為發現過往不少學員遇到這困擾,把網站做到位阻擋了課程銷售與SEO優化的進展速度,所以我決定直接幫你做到好(如果你有需要的話)。

Stable Diffusion 是一款免費開源的軟體,透過 AI 技術生成圖片。它可以根據使用者輸入的關鍵字生成相應的圖片作品。
Stable Diffusion 需要訓練以學習如何根據用戶輸入的關鍵字生成更符合需求的圖片。透過大量的訓練資料,AI 模型能更好地理解各種關鍵字,並生成更具創意和質量的圖片。
使用者可以使用Dream Studio網站,選擇使用 Google 帳號、Disco 帳號登入,或註冊新帳號。登入後即可免安裝使用 Stable Diffusion 生成圖片;有大約200張限制。而使用Stable Diffusion Demo則完全免費但需要較長等待時間。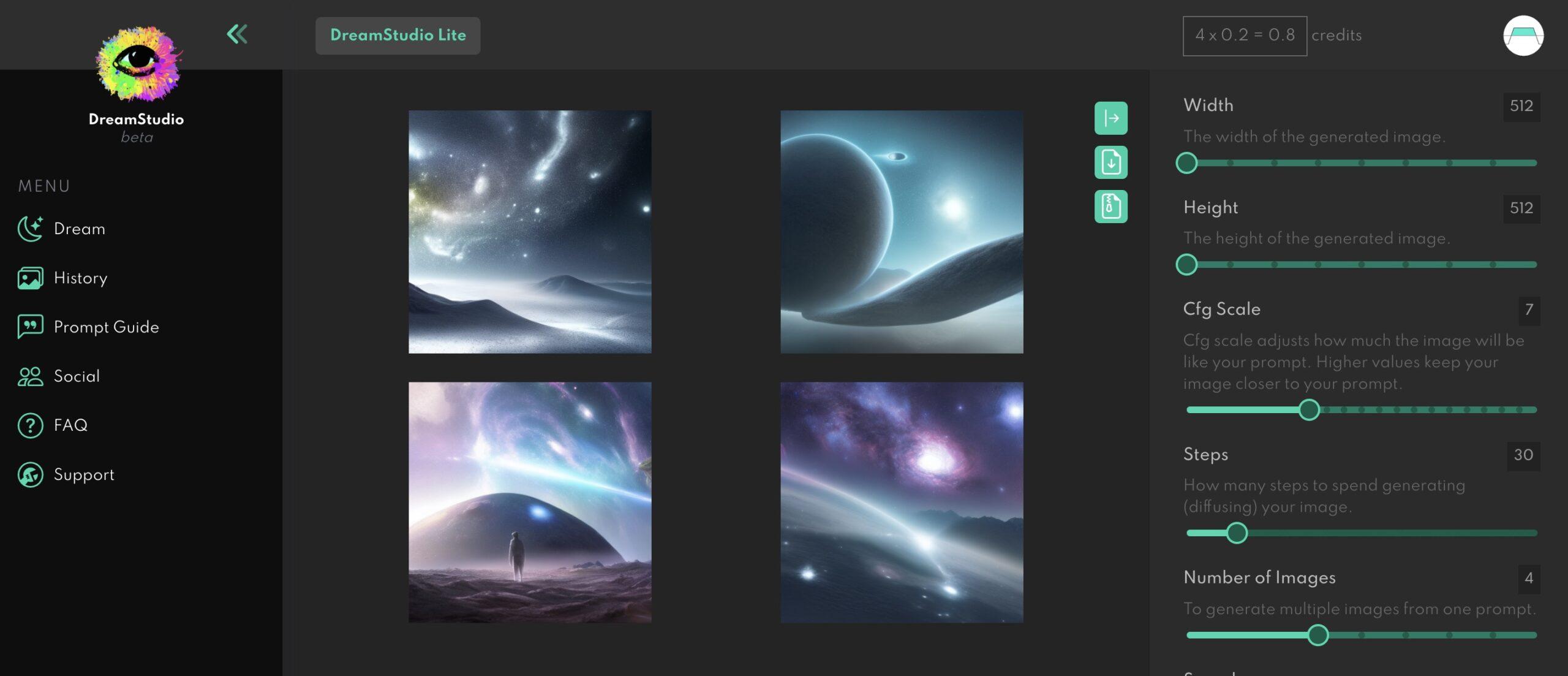

SEO文章是依照搜尋意圖撰寫、且結構符合...
Read more
